Puedes usar código como el siguiente (haciendo uso de la función as_latex) para generar un resultado de regresión a un archivo tex pero no los apila ordenadamente en forma tabular como lo hace outreg2:
import pandas as pd
import statsmodels.formula.api as smf
x = [1, 3, 5, 6, 8, 3, 4, 5, 1, 3, 5, 6, 8, 3, 4, 5, 0, 1, 0, 1, 1, 4, 5, 7]
y = [0, 1, 0, 1, 1, 4, 5, 7,0, 1, 0, 1, 1, 4, 5, 7,0, 1, 0, 1, 1, 4, 5, 7]
d = { "x": pd.Series(x), "y": pd.Series(y)}
df = pd.DataFrame(d)
mod = smf.ols('y ~ x', data=df)
res = mod.fit()
print(res.summary())
beginningtex = """\\documentclass{report}
\\usepackage{booktabs}
\\begin{document}"""
endtex = "\end{document}"
f = open('myreg.tex', 'w')
f.write(beginningtex)
f.write(res.summary().as_latex())
f.write(endtex)
f.close()
La función as_latex genera una tabla de latex válida pero no un documento de latex válido, así que agregué algo de código adicional arriba para que compile. El resultado es algo así para la función de imprimir:
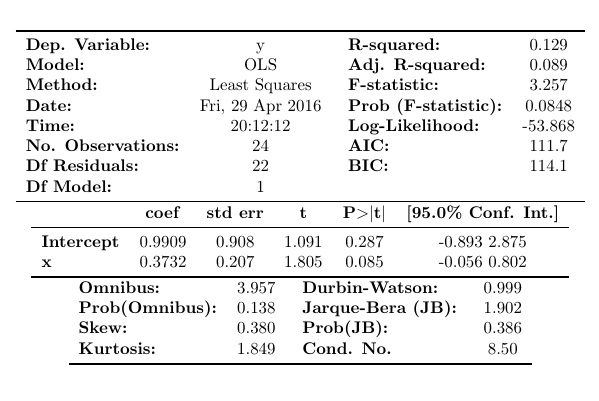
OLS Resultados de Regresión
==============================================================================
Variable Dependiente: y R-cuadrado: 0.129
Modelo: OLS R-Cuadrado Ajustado: 0.089
Método: Mínimos Cuadrados Estadística F: 3.257
Fecha: Viernes, 29 Abr 2016 Prob (Estadística F): 0.0848
Hora: 20:12:12 Log-Likelihood: -53.868
No. Observaciones: 24 AIC: 111.7
Gra Residuales: 22 BIC: 114.1
Gra Modelo: 1
Tipo de Covarianza: no robusta
==============================================================================
coef std err t P>|t| [95.0% Conf. Int.]
------------------------------------------------------------------------------
Intercepto 0.9909 0.908 1.091 0.287 -0.893 2.875
x 0.3732 0.207 1.805 0.085 -0.056 0.802
==============================================================================
Omnibus: 3.957 Durbin-Watson: 0.999
Prob(Omnibus): 0.138 Jarque-Bera (JB): 1.902
Asim: 0.380 Prob(JB): 0.386
Curtosis: 1.849 Cond. No. 8.50
==============================================================================
Advertencias:
[1] Los Errores Estándar asumen que la matriz de covarianza de los errores está especificada correctamente.
y así para el latex: ![introduce la descripción de la imagen aquí]()
Actualización: No tan completo como outreg, pero la función summary_col hace lo que solicitas.
import pandas as pd
import statsmodels.formula.api as smf
from statsmodels.iolib.summary2 import summary_col
x = [1, 3, 5, 6, 8, 3, 4, 5, 1, 3, 5, 6, 8, 3, 4, 5, 0, 1, 0, 1, 1, 4, 5, 7]
y = [0, 1, 0, 1, 1, 4, 5, 7,0, 1, 0, 1, 1, 4, 5, 7,0, 1, 0, 1, 1, 4, 5, 7]
d = { "x": pd.Series(x), "y": pd.Series(y)}
df = pd.DataFrame(d)
df['xsqr'] = df['x']**2
mod = smf.ols('y ~ x', data=df)
res = mod.fit()
print(res.summary())
df['xcube'] = df['x']**3
mod2= smf.ols('y ~ x + xsqr', data=df)
res2 = mod2.fit()
print(res2.summary())
mod3= smf.ols('y ~ x + xsqr + xcube', data=df)
res3 = mod3.fit()
print(res2.summary())
dfoutput = summary_col([res,res2,res3],stars=True)
print(dfoutput)
Lo cual tiene la siguiente salida:
=====================================
y I y II y III
-------------------------------------
Intercepto 0.9909 -0.6576 -0.2904
(0.9083) (1.0816) (1.3643)
x 0.3732* 1.7776*** 1.0700
(0.2068) (0.6236) (1.6736)
xcube -0.0184
(0.0402)
xsqr -0.1845** 0.0409
(0.0781) (0.4995)
=====================================
Errores estándar entre paréntesis.
* p<.1, ** p<.05, ***p<.01
Como antes, puedes usar dfoutput.as_latex() para exportar esto a latex.



{kind=link}
0 votos
P.s. este hilo podría ser más adecuado en las plataformas de análisis de datos, no estoy seguro...
3 votos
Estoy votando para cerrar esta pregunta como fuera de tema porque se trata de programación/comandos de Python y no de economía.